Data quality suddenly becomes a major component of the entire pipeline when AI and Machine Learning models are used in high-stakes fields like health and industrial automation. In the actual world, models are prone to numerous flaws that go unnoticed in a controlled setting.
For instance, model results can vary depending on the season. The wind can suddenly move a cascade of image sensors. According to Google’s study, even a tiny drop of water or oil can impact the information used to train a cancer prediction model. Before becoming evident in output, these minor deviations can go unnoticed for two to three years.
Google researchers want the entire community to consider the problem of Data Cascades seriously because of this. Almost 53 AI practitioners from India, East and West Africa, the US, and countries working on cutting-edge, high-stakes areas like health, wildlife conservation, food systems, road safety, credit, and the environment were surveyed about their practices and challenges.
According to the authors, at least one cascade had been encountered by 92% of the practitioners surveyed. Data cascades frequently start upstream (during data capture and gathering) and can have detrimental effects downstream (during model deployment and inference).
Because the effects frequently take time to manifest, cascades are an expensive and time-consuming problem in Machine Learning Lifecycle. Here we will discuss more about the everyday AI and Machine Learning development challenges data cascades bring and how to resolve them.
As the name implies, data cascades feature insignificant-appearing errors that add up to a disaster. While elusive, data cascades can be avoided. The following factors typically affect data flows, according to the researchers:
The researchers claim that because there are no pre-existing and curated datasets, model drifts are more frequent in high-stakes domains like sensing air quality or conducting an ultrasound scan. The so-called good versions perform well in a controlled laboratory environment. However, unique problems arise in the actual world.
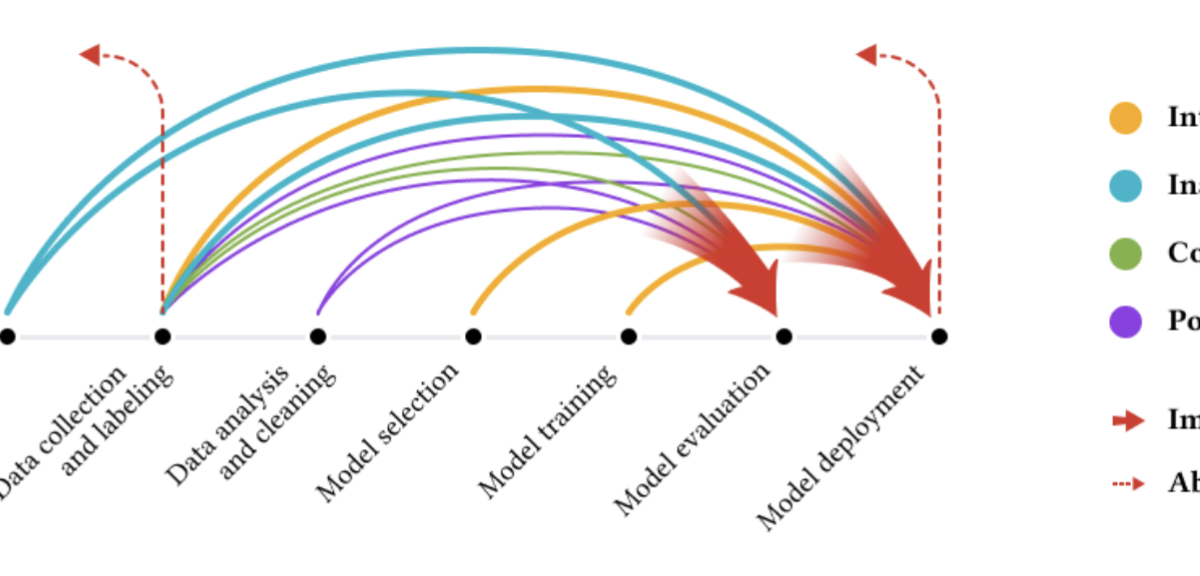
The Google Research team conducted interviews with practitioners who use AI apps that interact with data in the real world—downstream with sensors, cameras, and other data-gathering hardware, and upstream with data discovery and collection. Many problems in the actual world could lead to data cascades: “Data cascades frequently manifested as drifts in hardware, the surroundings, and human knowledge.”
Because there are no pre-existing and curated datasets, drifts are more frequent when models interact directly with new digital environments, such as high-risk domains like air quality sensing, ocean sensing, and ultrasound scanning. Such drifts may result in additional elements that worsen a model’s performance (e.g., related to hardware, environmental, and human knowledge).
When labeling data, it is a fairly common practice to seek the help of experts in the field. Researchers stress the value of full-cycle engagement with experts and depending on their knowledge throughout the machine learning lifecycle.
For example, certain data types, like identifying poaching hotspots or information gathered during underwater research, require knowledge of the biological sciences, social sciences, and local context. In this challenge, the practitioner must make decisions without the assistance of domain knowledge, discard data, merge data, analyze data & more. It sets off a data cascade.
In data science, poor documentation has long been an albatross (and many other industries). A robotics participant who took part in Google Research’s interviews expressed frustrations, saying that “collaborators changed the schema without understanding context, which resulted in the loss of four months of valuable medical robotics data gathering.”
Participants emphasized the value of metadata in “assessing quality, representativeness, and fit for use cases” and expressed irritation with the absence of standards for accurately describing datasets.
Inadequate or absent documentation makes high-stakes and specialized applications particularly vulnerable to data cascades, but missing metadata and context have an impact on AI applications.
Often, the priorities of practitioners, specialists, and stakeholders do not coincide. According to Google Research, the effects of this misalignment were “discovered well into deployment, through expensive iterations, moving to an alternate data source, or quitting the project entirely.”
Data gathering is frequently treated as a non-technical task and assigned to staff who may not be data literate, or it is abruptly added to the tasks of professionals already working in the field. It happens when data is not properly addressed. This lack of priority can result in problems with representative data, data providence, and incomplete data, all of which can cause data cascades.
There are no distinct indicators, tools, or metrics to detect and measure the effects of data cascades on the system, making both their diagnosis and manifestation opaque. In ML research and practice, dealing with data cascades necessitates a multifaceted, systemic approach in the machine learning lifecycle.
Developers and engineers who create web crawlers, data pipelines, and extract, load, and transform (ELT) tools should be familiar with the need to incorporate resilience into data gathering and extraction. The emergence of a new generation of businesses and startups primarily concerned with data pipelines and ELT further emphasizes the significance of data processing, storage, and transport.
It supports the need for continuous data quality monitoring, starting at the moment of collection and continuing through model deployment and inference. Companies should make sure their system for collecting data is adaptable enough to consider shifting laws and other aspects of society.
Non-technical professionals must be able to use the tools for data collection, labeling, preparation, and inspection. Generally, this entails working with subject-matter experts and potential users to create ML models.
For example, experts can assist with data inspection to ensure a model is not discriminatory. To construct more accurate models, they can also assist in gathering sample data or simulating it. Domain specialists understand data at a level that technologists cannot match.
It’s time to think outside the box when it comes to rewarding workers for their work on data (collection, labeling, cleaning, or maintenance) in companies or embracing empiricism on data in conference tracks.
Companies must take a more comprehensive view of data from collection to use as AI & Azure Machine Learning are used in more contexts and domains. The contributions of topic experts and data collectors should be incorporated into the data pipelines built by ML experts, and businesses should combine data literacy training for all stakeholders.
Any business developing machine learning products and services must have systems and procedures in place to ensure product quality from data collection to model training and deployment in order to stay competitive and successful. Although data cascades can begin anywhere, the researchers of Google Research discovered that they are usually started upstream.
Companies must incorporate tools and procedures for working with subject specialists who can offer guidance throughout the various phases of an Artificial Intelligence/Machine Learning pipeline, including data processing, data labeling, data collection, data inspection & data transformation to create robust applications.
Finally, it is crucial to emphasize and acknowledge documentation and metadata as crucial components of a successful machine-learning lifecycle. Early ML development initiatives can prevent data cascades. Wish to make your Machine Learning Lifecycle more streamlined and future-proof? Techmobius can help!
For businesses that want to develop products and services that are AI-enabled, overall data excellence will be crucial given the rising importance of Artificial Intelligence and Machine Learning. With our Artificial Intelligence Technology Solutions, we can address your development challenges. Reach out to us today!