In the ever-evolving landscape of technology, the intersection of language models and data extraction is paving the way for innovative solutions. One such advancement is the implementation of LangChain, a powerful framework designed for applications that leverage language models. This blog delves into the realm of metadata extraction using LangChain’s capabilities.
LangChain serves as a versatile platform for developing context-aware applications that harness the power of language models. The framework’s key strengths lie in its ability to connect language models to various sources of context, enabling applications to be inherently aware of their surroundings. Additionally, LangChain empowers applications to reason effectively, relying on language models for decision-making based on provided context.
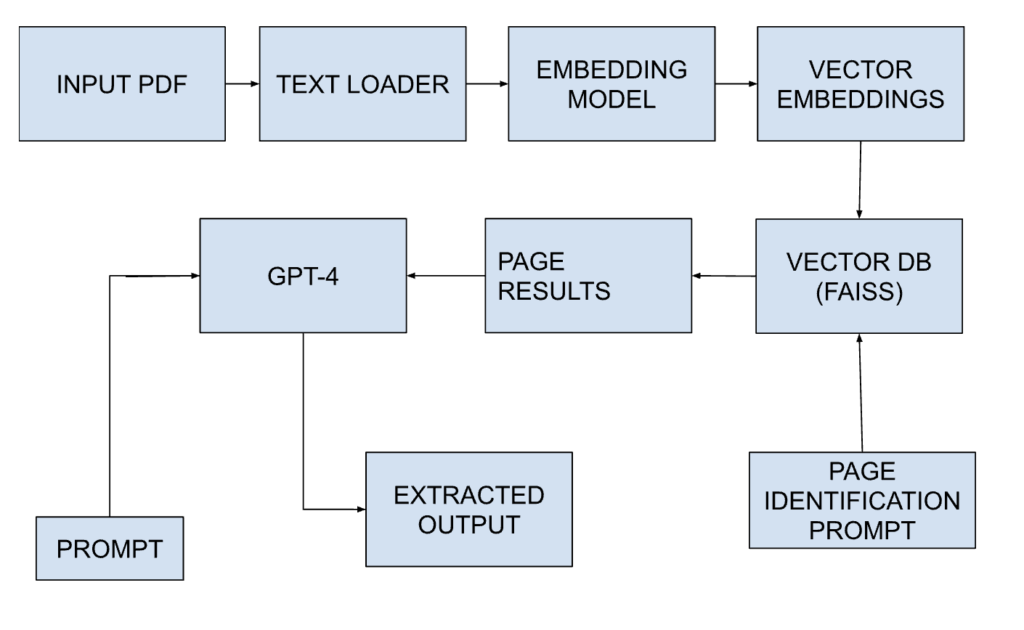
The Metadata Extraction Process

Fig 1 Text Document Loading and Vector Embeddings
2. Vector Embeddings with OpenAI’s Model Next in line is the transformation of the array of documents into vector embeddings, achieved through OpenAI’s text-embedding-ada-002 model. This step is crucial in converting textual information into numerical vectors, laying the foundation for efficient processing and analysis.
3. Vector Database with FAISS The vector embeddings find a home in the form of a vector database, where the efficiency and effectiveness of FAISS come into play. FAISS, an open-source library, excels in similarity search and clustering of dense vectors, providing a robust foundation for handling large-scale data.
4. Semantic Search with Keyword Prompts To identify pertinent pages within the vector database, keyword prompts are employed for semantic search. This strategic approach ensures that the relevant information is extracted with precision, setting the stage for the final phase.
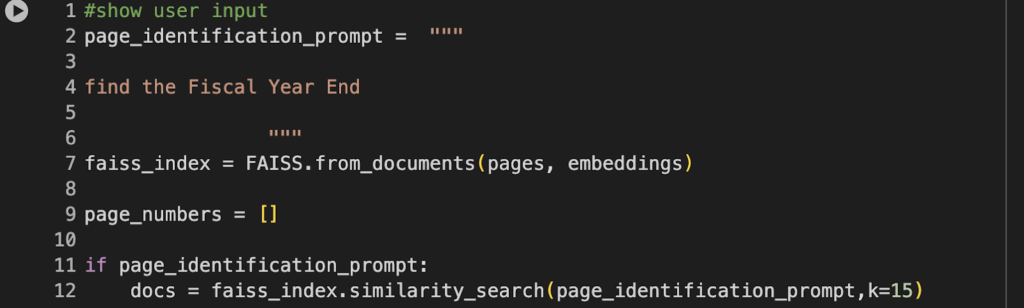
Fig 2 Semantic search with Keyword Prompts
5. GPT-4-Powered Metadata Extraction The cherry on top is the integration of GPT-4, a sophisticated language model, to extract metadata from the identified pages. The GPT-4 bot utilizes carefully crafted prompts to navigate through the documents and intelligently extract the desired information.
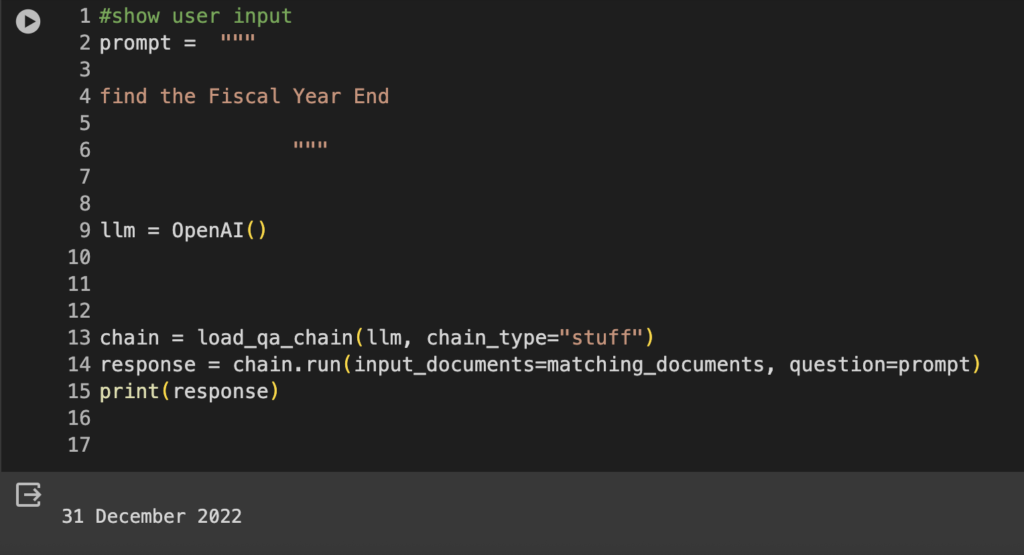
Fig 3 GPT-4 powered MetaData Extraction
In the realm of metadata extraction, LangChain emerges as a game-changer, seamlessly integrating language models, vector embeddings, and efficient search algorithms. The collaboration with OpenAI’s models and FAISS showcases the synergy of cutting-edge technologies, paving the way for context-aware and reasoning-driven applications. As we embrace the future of technology, the fusion of language models and metadata extraction through LangChain opens doors to new possibilities and advancements.
© Copyright 2026 TechMobius – A Mobius Knowledge Services Division. All Rights Reserved.