The Data Vault Model is a data modeling approach used in data warehousing and data integration. It is designed to manage large volumes of data with flexibility, scalability, and agility. The model consists of three main components: hubs, links, and satellites.
Hubs represent business entities or concepts and serve as the central point for integrating related data. Links capture the relationships between hubs, forming a network of connections. Satellites contain descriptive attributes and historical data associated with hubs and links. On the other hand, a dimensional model is a traditional data modeling approach used in data warehousing. It focuses on organizing data around business processes or dimensions, such as time, geography, and product. Dimensional models typically consist of fact tables and dimension tables, with the fact table containing numerical measures and the dimension table providing context and descriptive attributes.
The main difference between the Dimensional Model and the Data Vault Model lies in their design principles and purposes. The Dimensional Model is optimized for query performance and analytical reporting, providing a simplified and Denormalized structure. It is suitable for scenarios where the reporting requirements are well-defined and stable.
Data Vault Model prioritizes data integration, traceability, and scalability. It is designed to handle complex and changing business requirements, making it more suitable for scenarios where data integration and agility are crucial, such as building a data warehouse or data lake. The Data Vault Model’s flexibility allows for easier data integration from various sources and accommodates changes in business rules and data structures over time.
Data Governance: The Data Vault Model promotes data governance by providing a standardized and consistent approach to data modelling. It helps establish clear rules and guidelines for data integration, ensuring data quality, accuracy, and consistency across the organization.
Historical Data Tracking: The Data Vault Model excels at capturing and preserving historical data. It maintains a complete history of changes, allowing for analysis of data trends, patterns, and historical comparisons. This is valuable for business intelligence, trend analysis, and regulatory compliance.
Agile Data Integration: The Data Vault Model enables agile data integration by providing a framework that can handle diverse and rapidly changing data sources. It allows for incremental loading of data, making it easier to incorporate new sources and adapt to evolving business requirements.
Scalable Architecture: The Data Vault Model’s architecture is highly scalable, making it suitable for handling large volumes of data. It supports parallel processing and can be easily distributed across multiple servers or clusters, enabling efficient data processing and storage.
Data Lineage and Impact Analysis: The Data Vault Model facilitates data lineage and impact analysis. It provides a clear understanding of the origin and transformation of data, making it easier to track data lineage and assess the impact of changes on downstream processes and reports.
Flexibility for Data Marts and Data Lakes: The Data Vault Model serves as a foundation for building data marts and data lakes. It provides a flexible and extensible structure that can accommodate various reporting and analytics requirements, allowing for the creation of targeted data marts or the integration of data into a data lake architecture.
Collaboration and Teamwork: The Data Vault Model encourages collaboration and teamwork among data professionals. It provides a common language and framework for data modeling, facilitating communication and understanding between business analysts, data architects, and developers.
Future-Proofing: The Data Vault Model is designed to adapt to future changes in data sources, business rules, and reporting requirements. It provides a future-proof foundation that can evolve and scale with the organization’s data needs, reducing the risk of costly redesigns or migrations.
Scalability: The Data Vault Model is designed to handle large volumes of data and can easily accommodate new data sources and changing business requirements. It provides a flexible and scalable solution for data integration and storage.
Traceability: The Data Vault Model keeps a detailed history of all data changes, allowing for easy traceability and auditing. This is particularly useful for compliance and regulatory purposes.
Data Integration: The Data Vault Model allows for easy integration of data from multiple sources. It separates the management of business keys from the attributes of business entities, making it easier to handle complex relationships and data transformations.
Agility: The Data Vault Model provides agility in adapting to changing business needs. It allows for incremental updates and changes without impacting the entire data model, making it easier to maintain and evolve over time.
Background:
A multinational home and security products manufacturer company with a focus on brand leadership, innovation, and growth opportunities within the home, security, and commercial building markets. The project scope involves the integration of their existing ERP systems, including Oracle, SAP, SAGE, and Eclipse, Great Plains and others, into a unified system. The main goal of the project is to map the data from these systems into the centralized Snowflake Central System without replacing the existing ERP sources.
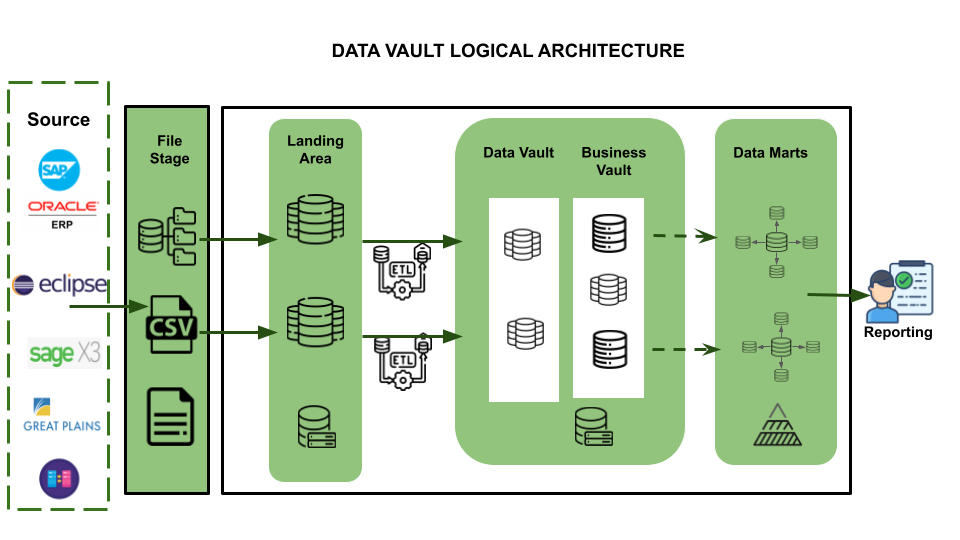
Mobius Solution:
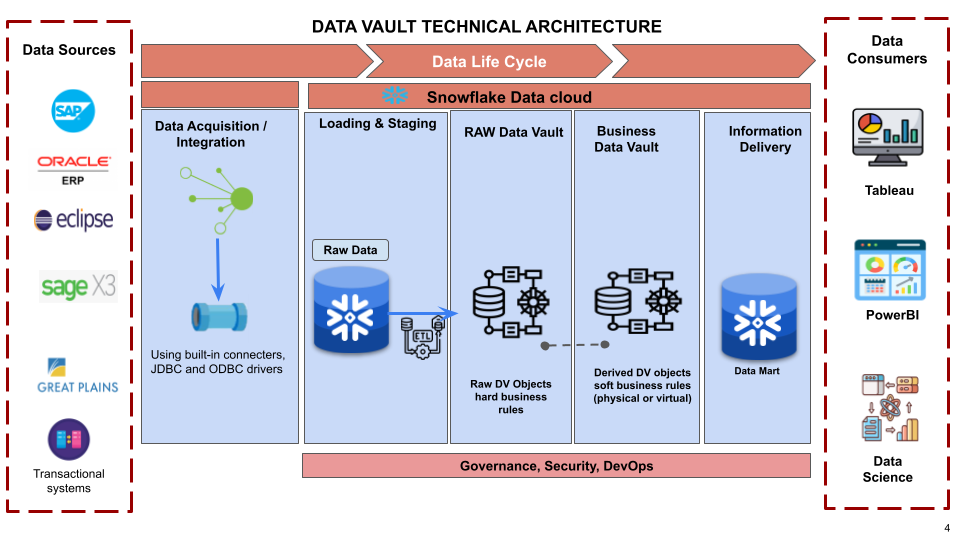
Source Systems: The primary data sources / ERP systems within our customer Ecosystem include SAP, 2 different versions of ORACLE, SAGE, Eclipse, Great Plains, and other transactional systems, etc.
Data Acquisition: The process entails extracting data from various source systems and rendering it accessible for Snowflake, thereby enabling seamless integration and analysis of the data.
Loading & Staging: The process involves transferring the source data into Snowflake, which offers the ability to load and store structured and semi-structured data in its original format while automatically optimizing the physical structure for efficient query access. From a Data Vault perspective, this layer is also responsible for adding technical metadata such as record source and load date timestamp, as well as calculating business keys. This ensures that the data is properly organized and can be easily accessed and analyzed for business insights.
Raw Data Vault: The approach involves implementing a data vault model that strictly adheres to hard business rules, with no soft rules or transformations applied. This means that all records received from the source are loaded into the data vault as is, without any modifications or alterations.
Business Data Vault: The approach involves implementing data vault objects with soft business rules applied, which augment the raw data vault data with the intelligence of the system. This allows for greater flexibility and organization in managing the data, as well as easier access to the specific data sets needed for analysis. By implementing soft business rules, the data vault model can be further optimized for efficient analysis and decision-making, while still maintaining the integrity and accuracy of the original data.
Data Consumers: The end users/team can leverage the Data Vault output for reporting through inbuilt native connection functionalities available within the PowerBI application (or) Python scripting for ML modelling and advanced analytics.
Our solution, which includes the implementation of an Integration Framework, data extraction, transformation, and loading processes, data mapping and integration using Data Vault modeling, and leveraging the Snowflake Central System, have enabled our client to achieve data centralization and streamline their operations effectively.
Thank you for reading.
© Copyright 2026 TechMobius – A Mobius Knowledge Services Division. All Rights Reserved.