The real-time data flow has a crucial effect on data engineers’ work and how apps are developed. Comparing real-time data flows to conventional integration and processing techniques involves a mindset change and an additional level of intricacy.
Leveraging real-time data analytics has legitimate advantages but requires careful planning for its input, processing, storage, and delivery. It changes how data consulting engineers operate and creates specialized operational requirements. When thinking about starting a real-time journey, these should be considered.
Nowadays, every firm is searching for ways to combine data from various sources to obtain business insights and acquire a competitive advantage. And that’s where data pipelines come into play! Let’s know more about it.
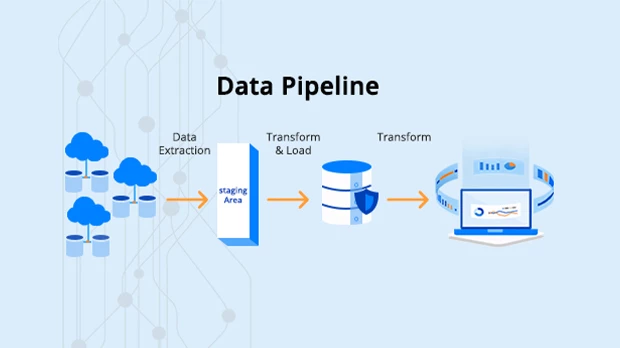
A data pipeline is a series of operations that transfers data from one location to another. Filtering, cleaning, combining, enriching & even studying data-in-motion are all possible steps in a pipeline.
Data pipelines transfer and combine data to make it appropriate for analytics and business intelligence from an elevated range of disparate sources and forms. Data networks also provide team members with the precise big data consulting they require without requiring access to private production systems.
The configuration of data pipelines to allow for the gathering, flow, and transmission of data is described in data pipeline designs.
Both batch processing and stream processing can transfer data. In batch processing, data sets are transferred once or periodically from sources to destinations. The tried-and-true traditional method of moving data is batch processing, but won’t allow for real-time research and observations.
In comparison, real-time data transfer is made possible by stream processing. A database’s update streams, communications systems, and sensor events are just a few examples of the data sources of data that stream processing constantly gathers. Real-time data analytics and decision-making are made possible by stream processing.
Data pipelines are an essential part of any real-time data analytics system. They provide a way to move data from one system to another and to process and analyze it precisely. With an accurate data pipeline, businesses can gain valuable insights into their customers, products, and operations.
Think of any pipe that gets something from a source and transfers it to a target to understand how a data pipeline works. The business use case and the final destination influence what occurs to the data along the path.
A data pipeline can be intended to manage data in a highly sophisticated way, such as training datasets for machine learning, or it can be a simple method of data extraction and loading.
Relational systems and data from SaaS apps are two examples of data sources. Most pipelines receive unprocessed data from various sources using a push method, an API call, a replication engine that periodically gets data, or a webhook. The synchronization of the data may also occur in reality or at predetermined periods.
A destination could be a data repository, such as a data warehouse, a data lake, or a data mart, such as on-premises, the cloud, or a BI/analytics tool.
Data processes such as data normalization, sorting, deduplication, validation, and verification are examples of transformation. Making it feasible to evaluate the data is the ultimate goal.
There are two types of data ingestion models: batch processing, which involves gathering source data regularly and sending it to the target system, and stream processing, which involves gathering, manipulating, and loading data as it is developed.
Workflow includes managing process dependencies and process orders. Dependencies in a workflow can be either business/technology-related.
To guarantee data security, data pipelines must include a tracking component. Network congestion and an offline source or target are two examples of possible failure situations. The pipeline must have a system to notify managers of such events.
So, how does real-time data pipelines work via streaming data pipeline? By extension, streaming data pipelines are a type of data pipeline design that can quickly and efficiently process millions of events. You can collect, examine, and keep much data as a consequence. Real-time apps, analytics, and monitoring are made possible by this feature.
The information entering the pipeline is the first stage in a streaming data pipeline. The software also decouples the creation of information from the apps that use it. It enables the creation of data streams with minimal latency (which can be transformed as necessary).
How does one initially enter application data into Kafka? The log is mined by CDC (change data capture) to retrieve the database’s unprocessed occurrences. An analytics system is connected to the streaming data network, enabling data consulting and analysis. Coworkers can use the information to respond to (and begin to handle) business-related concerns.
Building a data pipeline for real-time data analytics can be a complex process. It requires a deep understanding of the data sources, the data formats & the data analysis techniques. It also requires a robust infrastructure to ensure that data is securely moved from one system to another.
Fortunately, numerous tools and services are available to help businesses build and manage their data pipelines. These tools provide an easy way to integrate data sources, process data & monitor. With the right tools, companies can quickly gain insights into their customers, products, and operations.
A system that can manage batch, real-time analytics, and big data consulting and processing tasks is first essential; an example of this is Spark. To construct the streaming data flow, you will require a streaming medium (Kafka is a well-liked option, but got other choices on the global marketplace) to process it further.
Furthermore, a NoSQL database is also required (many people use HBase, but you have various choices available). The data must be modified, cleaned, validated, and written before you can create the streaming data strategies to ensure that it is in the proper format and is usable. The in-memory infrastructure get started before the streaming data flow is constructed.
You will then create the broadcast environment. The data must be retrieved from the streaming site & will be transformed. Monitoring the system to ensure everything is functioning as it should be is the final stage.
Building a data pipeline for real-time data analytics is a vital part for businesses that want to gain valuable insights into their customers, products, and operations. With the right tools and services, businesses can quickly and easily build and manage their data pipelines.
Knowing your company goals, identifying your data sources and destinations, and having the right tools are essential before you develop/implement a data pipeline. However, to keep up with the increasing complexity and quantity of datasets, data pipelines must be upgraded. While modernization requires time, effort, innovative and modern data pipelines will help teams make choices more quickly and effectively, giving them a competitive advantage.
However, establishing a reliable data pipeline doesn’t need to be difficult and time-consuming. Techmobius makes the process easy! Get the most from your data pipeline with a data analytics consulting company like ours!
© Copyright 2026 TechMobius – A Mobius Knowledge Services Division. All Rights Reserved.