- Home
- About
- Services
Data Engineering
and AnalyticsIndustries
Platforms
Verticals
Solutions
- Resources
- Partner with Us
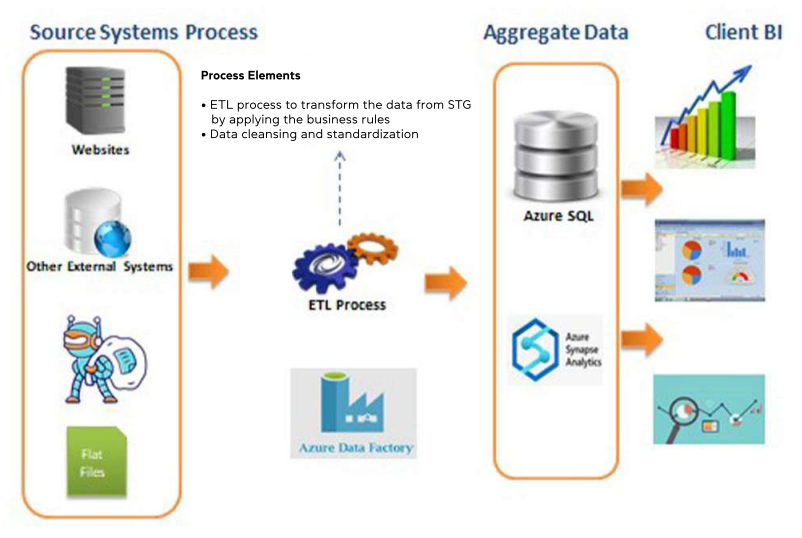
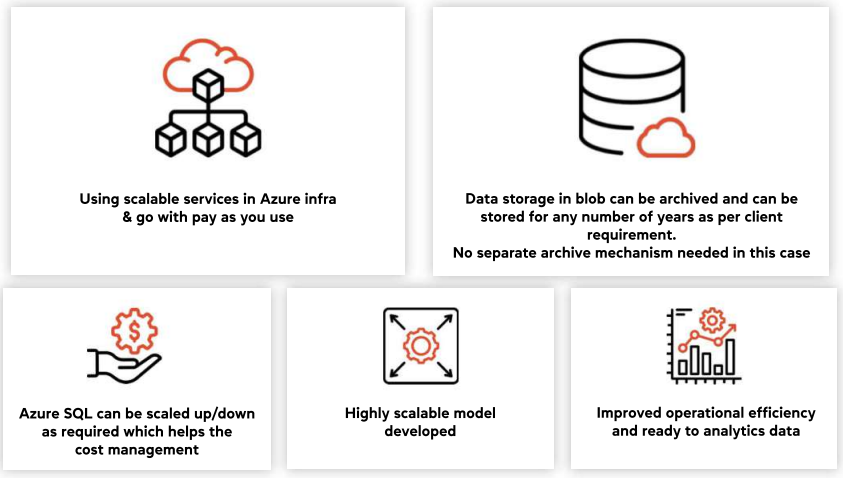

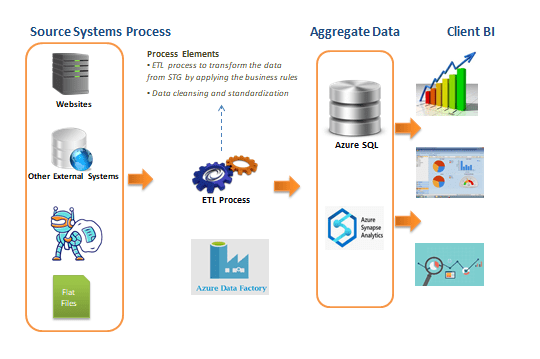

Price Monitoring Tool Price monitoring tool DevOps Case Study Client A leading Australian…

Reporting Tool Solution Reporting tool solution Data Consulting Case Study Client A Renowned…

Smart Product Classification Smart Product Classification Website Development Case Study Client A leading…
